Implementing XML languages with lxml
Dr. Stefan Behnel

What is an »XML language«?
- a language in XML notation
- aka »XML dialect«
- except that it's not a dialect
- Examples:
- XML Schema
- Atom/RSS
- (X)HTML
- Open Document Format
- SOAP
- ... add your own one here
Popular mistakes to avoid (1)
"That's easy, I can use regular expressions!"
No, you can't.
Popular mistakes to avoid (2)
"This is tree data, I'll take the DOM!"
Popular mistakes to avoid (2)
"This is tree data, I'll take the DOM!"
- DOM is ubiquitous, but it's as complicated as Java
- uglify your application with tons of DOM code to
- walk over non-element nodes to find the data you need
- convert text content to other data types
- modify the XML tree in memory
=> write verbose, redundant, hard-to-maintain code
Popular mistakes to avoid (3)
"SAX is so fast and consumes no memory!"
Popular mistakes to avoid (3)
"SAX is so fast and consumes no memory!"
- but writing SAX code is not fast!
- write error-prone, state-keeping SAX code to
- figure out where you are
- find the sections you need
- convert text content to other data types
- copy the XML data into custom data classes
- ... and don't forget the way back into XML!
=> write confusing state-machine code
=> debugging into existence
Working with XML
Getting XML work done
(instead of getting time wasted)
How can you work with XML?
- Preparation:
- Implement usable data classes as an abstraction layer
- Implement a mapping from XML to the data classes
- Implement a mapping from the data classes to XML
- Workflow:
- parse XML data
- map XML data to data classes
- work with data classes
- map data classes to XML
- serialise XML
- Approach:
- get rid of XML and do everything in your own code
What if you could simplify this?
- Preparation:
- Extend usable XML API classes into an abstraction layer
- Workflow:
- parse XML data into XML API classes
- work with XML API classes
- serialise XML
- Approach:
- cover only the quirks of XML and make it work for you
What if you could simplify this ...
- ... without sacrificing usability or flexibility?
- ... using a high-speed, full-featured, pythonic XML toolkit?
- ... with the power of XPath, XSLT and XML validation?
... then »lxml« is your friend!
Overview
- What is lxml?
- what & who
- How do you use it?
- Lesson 0: quick API overview
- ElementTree concepts and lxml features
- Lesson 1: parse XML
- how to get XML data into memory
- Lesson 2: generate XML
- how to write an XML generator for a language
- Lesson 3: working with XML trees made easy
- how to write an XML API for a language
- Lesson 0: quick API overview
What is lxml?
- a fast, full-featured toolkit for XML and HTML handling
- based on and inspired by
- the C libraries libxml2 and libxslt (by Daniel Veillard)
- the ElementTree API (by Fredrik Lundh)
- the Cython compiler (by Robert Bradshaw, Greg Ewing & me)
- the Python language (by Guido & [paste Misc/ACKS here])
- user feedback, ideas and patches (by you!)
- keep doing that, we love you all!
- maintained (and major parts) written by myself
- initial design and implementation by Martijn Faassen
- extensive HTML API and tools by Ian Bicking
What do you get for your money?
- many tools in one:
- Generic, ElementTree compatible XML API: lxml.etree
- but faster for many tasks and much more feature-rich
- Special tool set for HTML handling: lxml.html
- Special API for pythonic data binding: lxml.objectify
- General purpose path languages: XPath and CSS selectors
- Validation: DTD, XML Schema, RelaxNG, Schematron
- XSLT, XInclude, C14N, ...
- Fast tree iteration, event-driven parsing, ...
- Generic, ElementTree compatible XML API: lxml.etree
- it's free, but it's worth every €-Cent!
- what users say:
- »no qualification, I would recommend lxml for just about any HTML task«
- »THE tool [...] for newbies and experienced developers«
- »you can do pretty much anything with an intuitive API«
- »lxml takes all the pain out of XML«
- what users say:
Lesson 0: a quick overview
why »lxml takes all the pain out of XML«
(a quick overview of lxml features and ElementTree concepts)
Namespaces in ElementTree
uses Clark notation:
- wrap namespace URI in {...}
- append the tag name
>>> tag = "{http://www.w3.org/the/namespace}tagname" >>> element = etree.Element(tag)
no prefixes!
a single, self-containing tag identifier
Text content in ElementTree
uses .text and .tail attributes:
>>> div = html.fragment_fromstring( ... "<div><p>a paragraph<br>split in two</p> parts</div>") >>> p = div[0] >>> br = p[0] >>> p.text 'a paragraph' >>> br.text >>> br.tail 'split in two' >>> p.tail ' parts'
no text nodes!
- simplifies tree traversal a lot
- simplifies many XML algorithms
Attributes in ElementTree
uses .get() and .set() methods:
>>> root = etree.fromstring( ... '<root a="the value" b="of an" c="attribute"/>') >>> root.get('a') 'the value' >>> root.set('a', "THE value") >>> root.get('a') 'THE value'
or the .attrib dictionary property:
>>> d = root.attrib >>> list(sorted(d.keys())) ['a', 'b', 'c'] >>> list(sorted(d.values())) ['THE value', 'attribute', 'of an']
Tree iteration in lxml.etree (1)
>>> root = etree.fromstring(
... "<root> <a><b/><b/></a> <c><d/><e><f/></e><g/></c> </root>")
>>> print([child.tag for child in root]) # children
['a', 'c']
>>> print([el.tag for el in root.iter()]) # self and descendants
['root', 'a', 'b', 'b', 'c', 'd', 'e', 'f', 'g']
>>> print([el.tag for el in root.iterdescendants()])
['a', 'b', 'b', 'c', 'd', 'e', 'f', 'g']
>>> def iter_breadth_first(root):
... bfs_queue = collections.deque([root])
... while bfs_queue:
... el = bfs_queue.popleft() # pop next element
... bfs_queue.extend(el) # append its children
... yield el
>>> print([el.tag for el in iter_breadth_first(root)])
['root', 'a', 'c', 'b', 'b', 'd', 'e', 'g', 'f']
Tree iteration in lxml.etree (2)
>>> root = etree.fromstring(
... "<root> <a><b/><b/></a> <c><d/><e><f/></e><g/></c> </root>")
>>> tree_walker = etree.iterwalk(root, events=('start', 'end'))
>>> for (event, element) in tree_walker:
... print("%s (%s)" % (element.tag, event))
root (start)
a (start)
b (start)
b (end)
b (start)
b (end)
a (end)
c (start)
d (start)
d (end)
e (start)
f (start)
f (end)
e (end)
g (start)
g (end)
c (end)
root (end)
Path languages in lxml
<root>
<speech class='dialog'><p>So be it!</p></speech>
<p>stuff</p>
</root>
search it with XPath
>>> find_paragraphs = etree.XPath("//p") >>> paragraphs = find_paragraphs(xml_tree) >>> print([ p.text for p in paragraphs ]) ['So be it!', 'stuff']
search it with CSS selectors
>>> find_dialogs = cssselect.CSSSelector("speech.dialog p") >>> paragraphs = find_dialogs(xml_tree) >>> print([ p.text for p in paragraphs ]) ['So be it!']
Summary of lesson 0
- lxml comes with various tools
- that aim to hide the quirks of XML
- that simplify finding and handling data
- that make XML a pythonic tool by itself
Lesson 1: parsing XML/HTML
The input side
(a quick overview)
Parsing XML and HTML from ...
- strings: fromstring(xml_data)
- byte strings, but also unicode strings
- filenames: parse(filename)
- HTTP/FTP URLs: parse(url)
- file objects: parse(f)
- f = open(filename, 'rb') !
- file-like objects: parse(f)
- only need a f.read(size) method
- data chunks: parser.feed(xml_chunk)
- result = parser.close()
(parsing from strings and filenames/URLs frees the GIL)
Example: parsing from a string
using the fromstring() function:
>>> root_element = etree.fromstring(some_xml_data)
using the fromstring() function with a specific parser:
>>> parser = etree.HTMLParser(remove_comments=True) >>> root_element = etree.fromstring(some_html_data, parser)
or the XML() and HTML() aliases for literals in code:
>>> root_element = etree.XML("<root><child/></root>") >>> root_element = etree.HTML("<p>some<br>paragraph</p>")
Parsing XML into ...
- a tree in memory
- parse() and fromstring() functions
- a tree in memory, but step-by-step with a generator
- iterparse() generates (start/end, element) events
- tree can be cleaned up to save space
- SAX-like callbacks without building a tree
- parse() and fromstring() functions
- pass a target object into the parser
Summary of lesson 1
- parsing XML/HTML in lxml is mostly straight forward
- simple functions that do the job
- advanced use cases are pretty simple
- event-driven parsing using iterparse()
- special parser configuration with keyword arguments
- configuration is generally local to a parser
- BTW: parsing is very fast, as is serialising
- don't hesitate to do parse-serialise-parse cycles
Lesson 2: generating XML
The output side
(and how to make it safe and simple)
The example language: Atom
The Atom XML format
- Namespace: http://www.w3.org/2005/Atom
- W3C recommendation derived from RSS and friends
- Atom feeds describe news entries and annotated links
- a feed contains one or more entry elements
- an entry contains author, link, summary and/or content
Example: generate XML (1)
The ElementMaker (or E-factory)
>>> from lxml.builder import ElementMaker
>>> A = ElementMaker(namespace="http://www.w3.org/2005/Atom",
... nsmap={None : "http://www.w3.org/2005/Atom"})
>>> atom = A.feed(
... A.author( A.name("Stefan Behnel") ),
... A.entry(
... A.title("News from lxml"),
... A.link(href="http://codespeak.net/lxml/"),
... A.summary("See what's <b>fun</b> about lxml...",
... type="html"),
... )
... )
>>> from lxml.etree import tostring
>>> print( tostring(atom, pretty_print=True) )
Example: generate XML (2)
>>> atom = A.feed(
... A.author( A.name("Stefan Behnel") ),
... A.entry(
... A.title("News from lxml"),
... A.link(href="http://codespeak.net/lxml/"),
... A.summary("See what's <b>fun</b> about lxml...",
... type="html"),
... )
... )
<feed xmlns="http://www.w3.org/2005/Atom">
<author>
<name>Stefan Behnel</name>
</author>
<entry>
<title>News from lxml</title>
<link href="http://codespeak.net/lxml/"/>
<summary type="html">See what's <b>fun</b>
about lxml...</summary>
</entry>
</feed>
Be careful what you type!
>>> atom = A.feed(
... A.author( A.name("Stefan Behnel") ),
... A.entry(
... A.titel("News from lxml"),
... A.link(href="http://codespeak.net/lxml/"),
... A.summary("See what's <b>fun</b> about lxml...",
... type="html"),
... )
... )
<feed xmlns="http://www.w3.org/2005/Atom">
<author>
<name>Stefan Behnel</name>
</author>
<entry>
<titel>News from lxml</titel>
<link href="http://codespeak.net/lxml/"/>
<summary type="html">See what's <b>fun</b>
about lxml...</summary>
</entry>
</feed>
Want more 'type safety'?
Write an XML generator module instead:
# atomgen.py
from lxml import etree
from lxml.builder import ElementMaker
ATOM_NAMESPACE = "http://www.w3.org/2005/Atom"
A = ElementMaker(namespace=ATOM_NAMESPACE,
nsmap={None : ATOM_NAMESPACE})
feed = A.feed
entry = A.entry
title = A.title
# ... and so on and so forth ...
# plus a little validation function: isvalid()
isvalid = etree.RelaxNG(file="atom.rng")
The Atom generator module
>>> import atomgen as A
>>> atom = A.feed(
... A.author( A.name("Stefan Behnel") ),
... A.entry(
... A.link(href="http://codespeak.net/lxml/"),
... A.title("News from lxml"),
... A.summary("See what's <b>fun</b> about lxml...",
... type="html"),
... )
... )
>>> A.isvalid(atom) # ok, forgot the ID's => invalid XML ...
False
>>> title = A.titel("News from lxml")
Traceback (most recent call last):
...
AttributeError: 'module' object has no attribute 'titel'
Mixing languages (1)
Atom can embed serialised HTML
>>> import lxml.html.builder as h
>>> html_fragment = h.DIV(
... "this is some\n",
... h.A("HTML", href="http://w3.org/MarkUp/"),
... "\ncontent")
>>> serialised_html = etree.tostring(html_fragment, method="html")
>>> summary = A.summary(serialised_html, type="html")
>>> print(etree.tostring(summary))
<summary xmlns="http://www.w3.org/2005/Atom" type="html">
<div>this is some
<a href="http://w3.org/MarkUp/">HTML</a>
content</div>
</summary>
Mixing languages (2)
Atom can also embed non-escaped XHTML
>>> from copy import deepcopy
>>> xhtml_fragment = deepcopy(html_fragment)
>>> from lxml.html import html_to_xhtml
>>> html_to_xhtml(xhtml_fragment)
>>> summary = A.summary(xhtml_fragment, type="xhtml")
>>> print(etree.tostring(summary, pretty_print=True))
<summary xmlns="http://www.w3.org/2005/Atom" type="xhtml">
<html:div xmlns:html="http://www.w3.org/1999/xhtml">this is some
<html:a href="http://w3.org/MarkUp/">HTML</html:a>
content</html:div>
</summary>
Summary of lesson 2
- generating XML is easy
- use the ElementMaker
- wrap it in a module that provides
- the target namespace
- an ElementMaker name for each language element
- a validator
- maybe additional helper functions
- mixing languages is easy
- define a generator module for each
... this is all you need for the output side of XML languages
Lesson 3: Designing XML APIs
The Element API
(and how to make it the way you want)
Trees in C and in Python
- Trees have two representations:
- a plain, complete, low-level C tree provided by libxml2
- a set of Python Element proxies, each representing one element
- Proxies are created on-the-fly:
- lxml creates an Element object for a C node on request
- proxies are garbage collected when going out of scope
- XML trees are garbage collected when deleting the last proxy
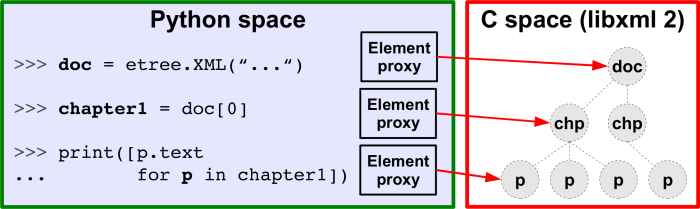
Mapping Python classes to nodes
- Proxies can be assigned to XML nodes by user code
- lxml tells you about a node, you return a class
Example: a simple Element class (1)
define a subclass of ElementBase
>>> class HonkElement(etree.ElementBase): ... @property ... def honking(self): ... return self.get('honking') == 'true'
let it replace the default Element class
>>> lookup = etree.ElementDefaultClassLookup( ... element=HonkElement) >>> parser = etree.XMLParser() >>> parser.set_element_class_lookup(lookup)
Example: a simple Element class (2)
use the new Element class
>>> root = etree.XML('<root><honk honking="true"/></root>', ... parser) >>> root.honking False >>> root[0].honking True
Mapping Python classes to nodes
- The Element class lookup
- lxml tells you about a node, you return a class
- no restrictions on lookup algorithm
- each parser can use a different class lookup scheme
- lookup schemes can be chained through fallbacks
- Classes can be selected based on
- the node type (element, comment or processing instruction)
- ElementDefaultClassLookup()
- the namespaced node name
- CustomElementClassLookup() + a fallback
- ElementNamespaceClassLookup() + a fallback
- the value of an attribute (e.g. id or class)
- AttributeBasedElementClassLookup() + a fallback
- read-only inspection of the tree
- PythonElementClassLookup() + a fallback
- the node type (element, comment or processing instruction)
Designing an Atom API
a feed is a container for entries
# atom.py ATOM_NAMESPACE = "http://www.w3.org/2005/Atom" _ATOM_NS = "{%s}" % ATOM_NAMESPACE class FeedElement(etree.ElementBase): @property def entries(self): return self.findall(_ATOM_NS + "entry")
it also has a couple of meta-data children, e.g. title
class FeedElement(etree.ElementBase): # ... @property def title(self): "return the title or None" return self.find("title")
Consider lxml.objectify
- ready-to-use, generic Python object API for XML
>>> from lxml import objectify
>>> feed = objectify.parse("atom-example.xml")
>>> print(feed.title)
Example Feed
>>> print([entry.title for entry in feed.entry])
['Atom-Powered Robots Run Amok']
>>> print(feed.entry[0].title)
Atom-Powered Robots Run Amok
Still room for more convenience
from itertools import chain
class FeedElement(objectify.ObjectifiedElement):
def addIDs(self):
"initialise the IDs of feed and entries"
for element in chain([self], self.entry):
if element.find(_ATOM_NS + "id") is None:
id = etree.SubElement(self, _ATOM_NS + "id")
id.text = make_guid()
Incremental API design
- choose an XML API to start with
- lxml.etree is general purpose
- lxml.objectify is nice for document-style XML
- fix Elements that really need some API sugar
- dict-mappings to children with specific content/attributes
- properties for specially typed attributes or child values
- simplified access to varying content types of an element
- shortcuts for unnecessarily deep subtrees
- ignore what works well enough with the Element API
- lists of homogeneous children -> Element iteration
- string attributes -> .get()/.set()
- let the API grow at your fingertips
- play with it and test use cases
- avoid "I want because I can" feature explosion!
Setting up the Element mapping
Atom has a namespace => leave the mapping to lxml
# ...
_atom_lookup = etree.ElementNamespaceClassLookup(
objectify.ObjectifyElementClassLookup())
# map the classes to tag names
ns = _atom_lookup.get_namespace(ATOM_NAMESPACE)
ns["feed"] = FeedElement
ns["entry"] = EntryElement
# ... and so on
# or use ns.update(vars()) with appropriate class names
# create a parser that does some whitespace cleanup
atom_parser = etree.XMLParser(remove_blank_text=True)
# make it use our Atom classes
atom_parser.set_element_class_lookup(_atom_lookup)
# and help users in using our parser setup
def parse(input):
return etree.parse(input, atom_parser)
Using your new Atom API
>>> import atom
>>> feed = atom.parse("ep2008/atom-example.xml").getroot()
>>> print(len(feed.entry))
1
>>> print([entry.title for entry in feed.entry])
['Atom-Powered Robots Run Amok']
>>> link_tag = "{%s}link" % atom.ATOM_NAMESPACE
>>> print([link.get("href") for link in feed.iter(link_tag)])
['http://example.org/', 'http://example.org/2003/12/13/atom03']
Summary of lesson 3
To implement an XML API ...
- start off with lxml's Element API
- or take a look at the object API of lxml.objectify
- specialise it into a set of custom Element classes
- map them to XML tags using one of the lookup schemes
- improve the API incrementally while using it
- discover inconveniences and beautify them
- avoid putting work into things that work
Conclusion
lxml ...
- provides a convenient set of tools for XML and HTML
- parsing
- generating
- working with in-memory trees
- follows Python idioms wherever possible
- highly extensible through wrapping and subclassing
- callable objects for XPath, CSS selectors, XSLT, schemas
- iteration for tree traversal (even while parsing)
- list-/dict-like APIs, properties, keyword arguments, ...
- makes extension and specialisation easy
- write a special XML generator module in trivial code
- write your own XML API incrementally on-the-fly